
S
Seth Meldon
Guest
The Progress Corticon Business Rules Management System automates mortgage approval while allowing experts to create and manage the rules.
This rule modeling case study examines how the Corticon Business Rules Management System provides a way to automate this complex scenario yet still provide the flexibility for the business experts to create and manage the rules.
Should this loan application be approved, rejected or referred for further consideration?
To make this decision we will need some rules.
Here are two of the sample rules provided by the lender (there are more which we will introduce during the modeling exercise):
1. We do not currently do non owner-occupied loans
2. Loans under 80% LTV may be automatically approved
We will walk through the entire process of modeling these rules, including the discovery of errors, ambiguities and incompleteness using Corticon Studio.
We’ll find that even these two apparently simple rules contain problems which Corticon will help us discover and resolve.
By referring to the rule statements we can deduce the existence of objects like a loan—the entities being considered for approval.
We can also deduce that a loan will have some attributes such as:
Status is what the rules are being asked to determine.
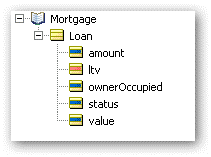
This will be modeled in the Corticon vocabulary:
This helps to make sure the data model makes sense.
This can be done in the Corticon Testing tool which is built into Corticon.
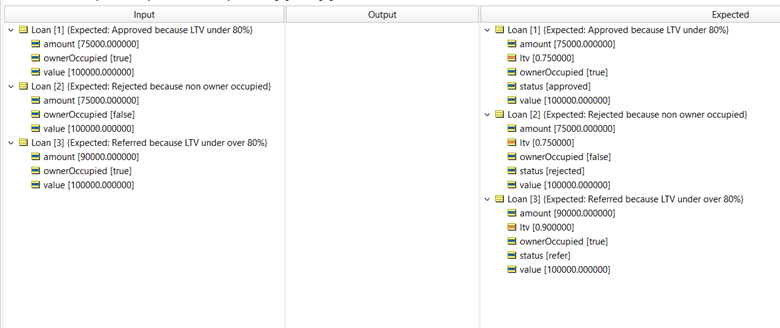
We can also set up some expected results to verify that our rules are producing the answers we expect.
We’ll see during the demo how Corticon will automatically compare the actual and expected results and flag any variations once the rules have filled in the output column.
There are no hard and fast rules about how to divide up the rules into groups, but a good way to start is to group the rules according to the main attribute that they are determining.
In this example we only have one sheet.
These are the rule statements that would be on the rulesheet. The rule statements are always the starting point for rule modeling.

Now we are ready to model the rules.
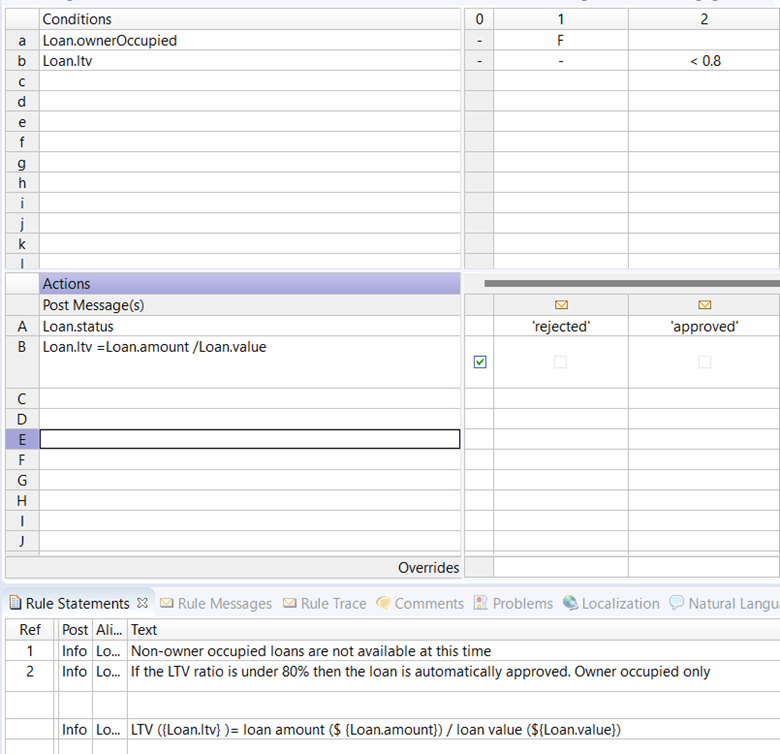
Here’s what the rules might look like:
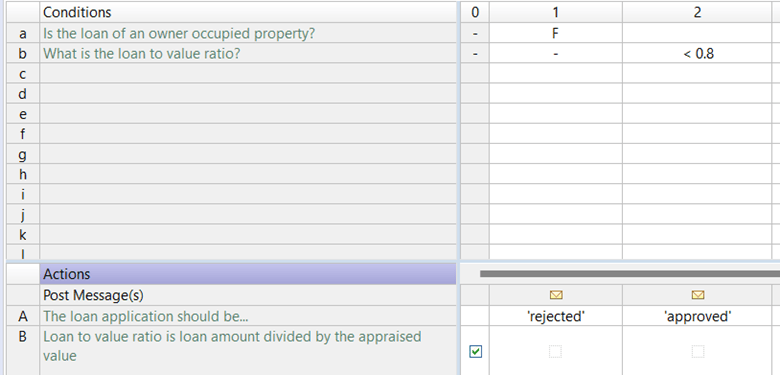
Note that it’s also possible to toggle this view to a natural language view:
At this point it appears that we are done. Our rules seem to correspond to what was in the original specification. But are they correct?
If we were developing these rules in a programming language or even a different rule engine we’d probably need to run some tests to see if the rules are correct.
In the Corticon world we don’t believe that’s the most effective way of finding errors and so Corticon has built into Studio some tools for checking the rule model.
However, for the purposes of this case study, let’s do things that way other rule engines would have to do it—with test data.
We already have some test data and expected results so we can run our rules.
This is what we will get:
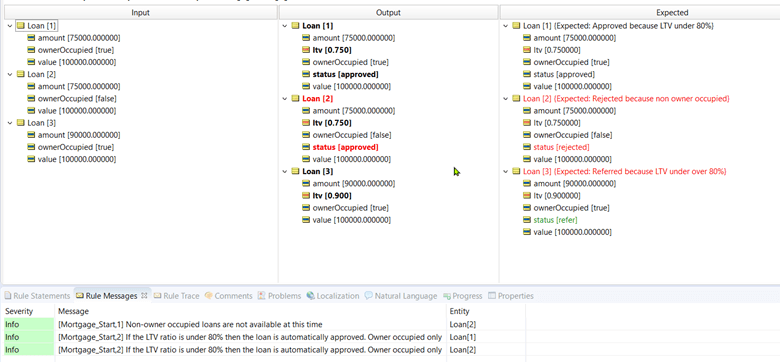
Note the second test case is highlighted in red because the actual result did not match the expected result.
But why is that?
If we select loan[2] in the middle column, you will see that two rule statements are highlighted below—these are the ones that apply to loan[2].
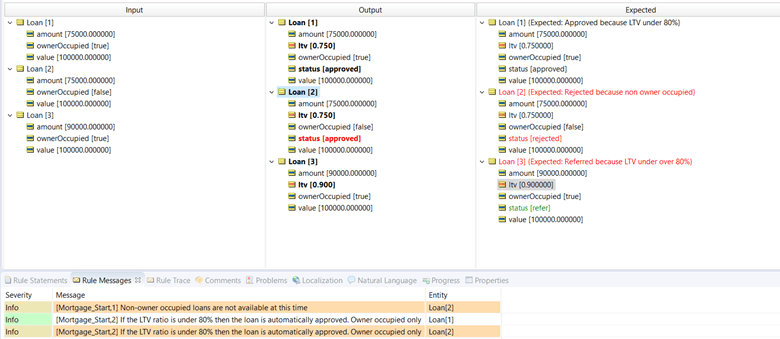
Notice that the first did get the correct answer. However, a second rule also fired and overwrote the correct answer with an incorrect answer.
This is what we call a rule conflict or ambiguity.
Now we discovered this with test data—and for this simple example there aren’t very many possible test cases. But in the real world there may be thousands or millions of possible test cases. The chances of finding problems that way are very slim and often don’t happen until the rules are in production and an angry customer complains.
Corticon has a much better way.
Let’s return to the rule sheet and see how Corticon can find this problem without the need for test data.
If we run the conflict checker, we’ll see this:
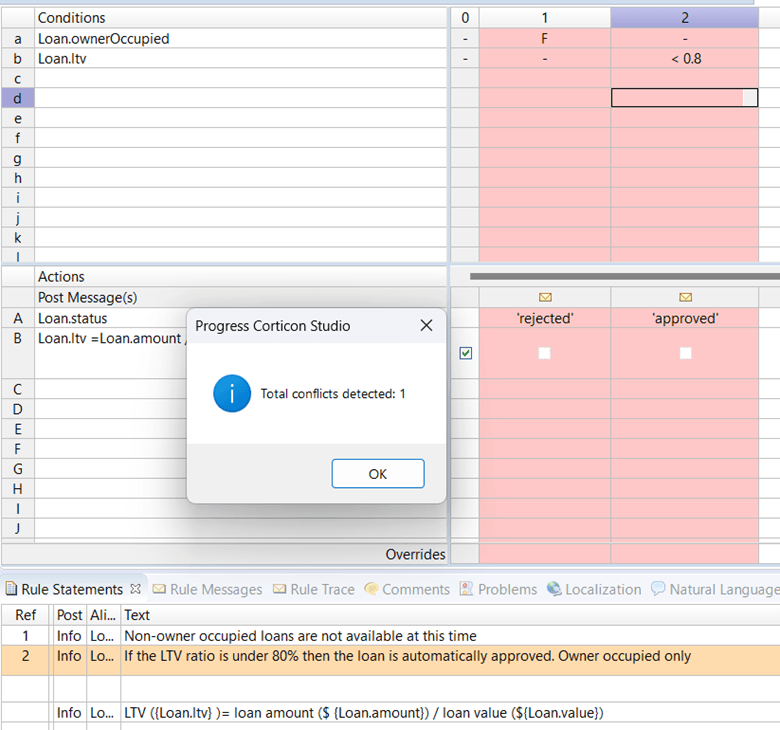
Corticon has determined that the conditions are not sufficient to distinguish these two rules and since they have different actions it considers them a potential ambiguity.
So, how do we resolve it?
Well, you might say, “Just put them in the other order and everything will be fine.”
Yes, in this simple case that’s true, but when there are dozens of rules it may not be obvious what the correct order is. And in any case, it’s the rule engine’s job to figure out the order.
In order to resolve this, we need to clarify the intent of the rules.
As specified it appears that rule 2 was intended to deal owner occupied loans.
This can be modeled as follows:
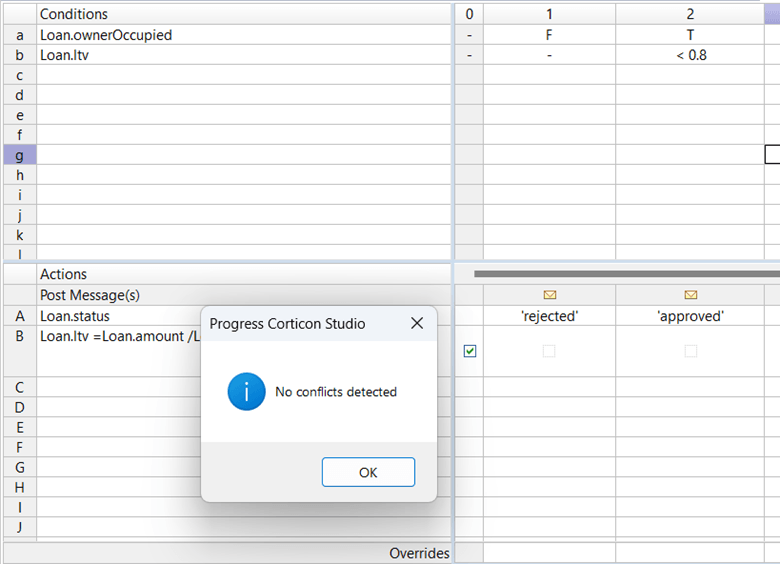
And now, without having to run any test cases, Corticon can confirm that this is ambiguity free.
If we choose to rerun the test case we will find that we now get the expected answer for loan 2:
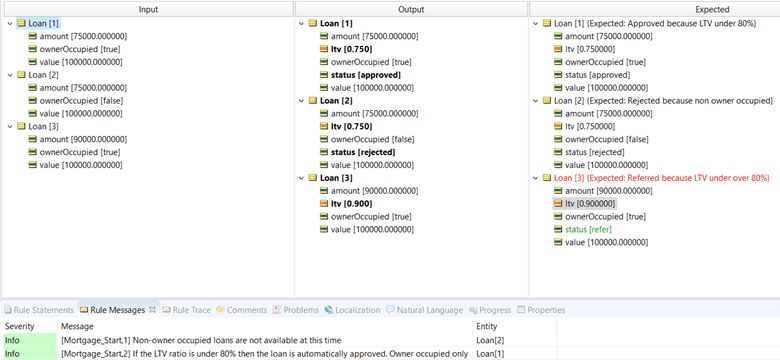
But notice that we still have a discrepancy. Loan 3 did not get a status assigned. That means somehow our rules are incomplete.
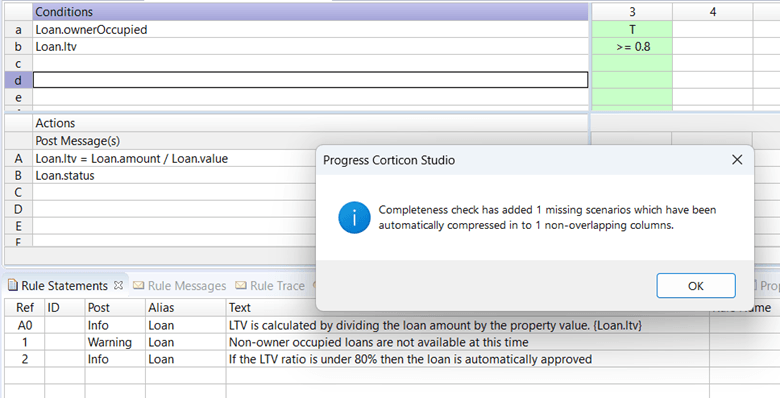
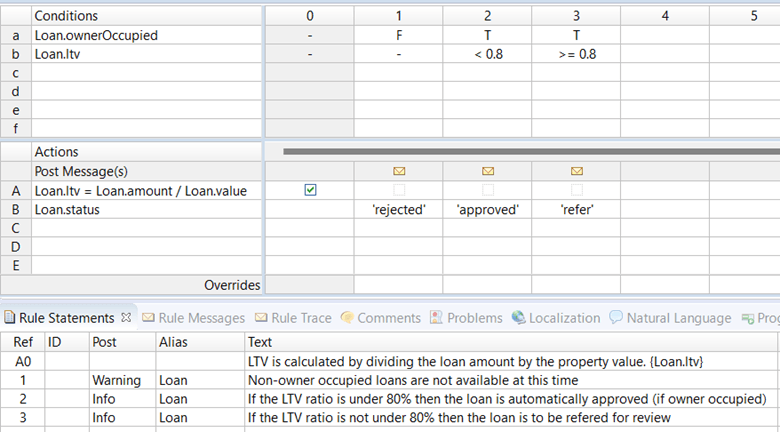
We can run the completeness checker and Corticon will identify any missing rules:
Rules rarely stay the same for very long.
So we might imagine that this first rulesheet represents our default approval rules that apply to everyone.
Suppose one of our clients (say client XYZ) want to use slightly different rules for all of their loan approvals.
We have a number of ways we can implement this:
1. We can provide an alternative rulesheet that applies just to client XYZ.
2. We can allow client XYZ’s rules to override our default rules.
3. We can constrain client XYZs rules to fit within our default rules.
The first step is to create a fresh rulesheet for client XYZ. This is done by copy/pasting the existing rulesheet.
Then we need to do two things:
1. Indicate that this new sheet applies only to client XYZ.
2. Make the changes that are specific to XYZ.
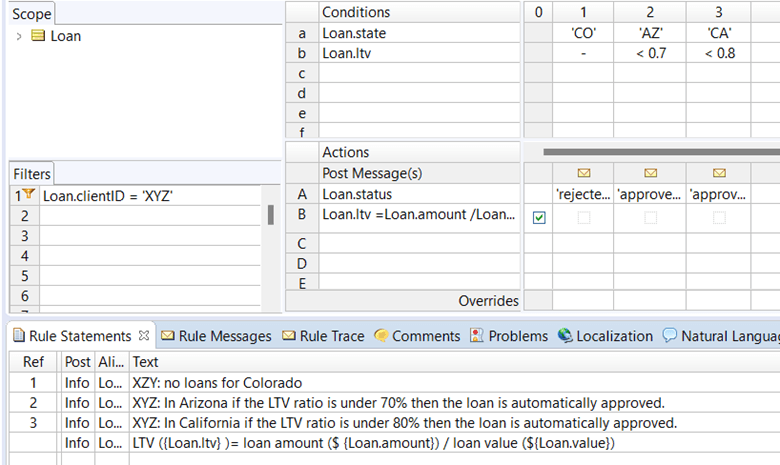
Here’s what that might look like:
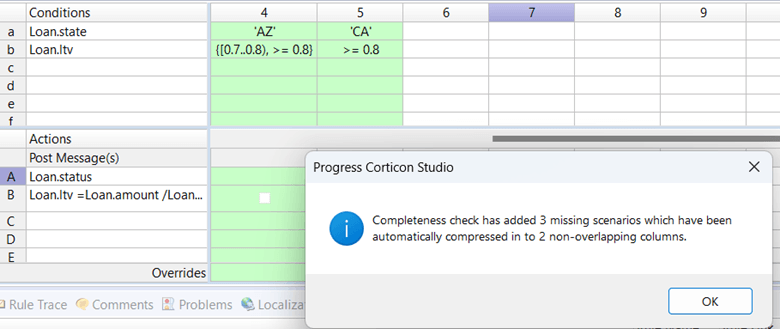
Of course, we should check this for completeness and consistency, and Corticon will discover that we are missing some rules:
Now that we have two rulesheets (one generic and one for XYZ) we can configure them using the ruleflow:
In the first ruleflow, the global rules go first and the XYZ rules can override them.
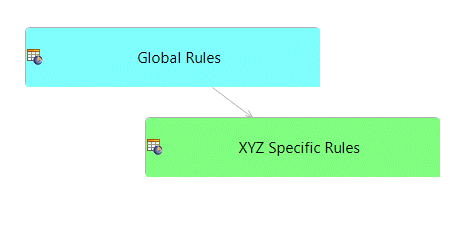
In the second case, the XYZ rules go first but can be constrained or overridden by the global rules.

Only XYZ users would be able to change the XYZ rules, whereas corporate users would be able to change the Global rules (and the XYZ rules if needed).
We can specify effective dates for a rule flow:
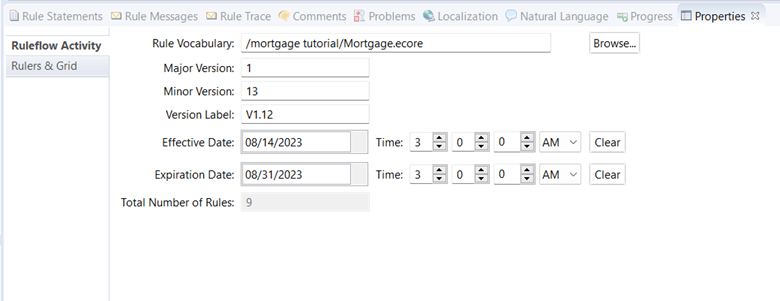
This dialog specifies that the rule flow will become effective on 8/14/2023 and expire on 8/31/2023.
If a rule flow with a higher version number is deployed with an overlapping effective date, then that new one will supersede this one.
Most rule engines can model the simple rules that we’ve looked at so far.
But they may not be able to handle the analysis and testing quite so well.
What happens when it gets more complex?
It can get more complex in two ways:
1. More attributes, more conditions and more combinations of conditions
2. More complex data structures and relationships between them
In this section we’ll look at how Corticon’s unique features make it easy for a businessperson to model rules that must deal with complex data structures. In many other rule engines this is a task that may have to be done by a programmer.
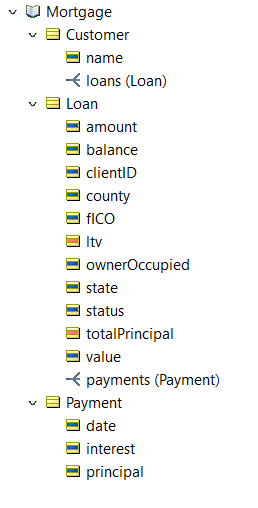
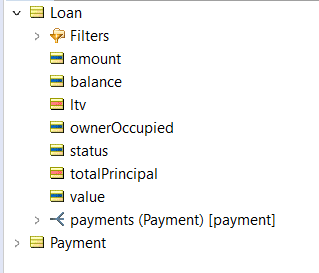
Loans are usually associated with customers and loans will typically have one or more payments.
This leads to the following vocabulary:
Here’s a sample of some data that conforms to this structure:
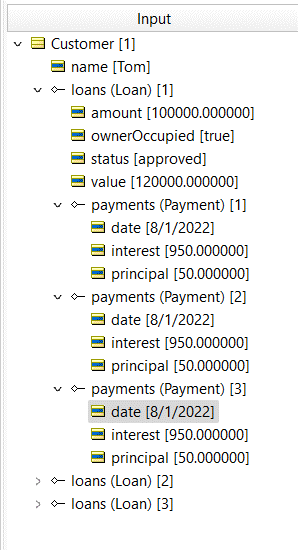
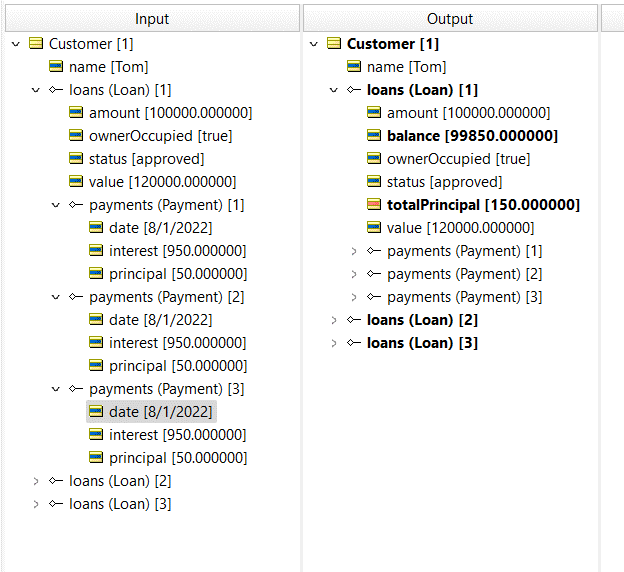
Suppose we want to sum the principal payments to determine the outstanding balance.
The key to this is Corticon’s concept of SCOPE.
When we do the summing of amounts, we want to make sure that it’s the sum of the transactions that belong to the accounts that belong to the client.
To indicate this hierarchy, we drag the entities into the scope section:
We can also create aliases to the business objects. This will allow us to write more concise rules.
To compute the amount total we can now do something very similar to what you would do in Excel—we use the SUM operator:

Here’s a small test case:
Here are some of the other operators that are available for dealing with collections:

Once the rule model is complete it can be deployed to the Corticon execution engine.
Corticon offers various modes of execution:
For the Web Services option, the Corticon Web Console can be used for management of decision services.
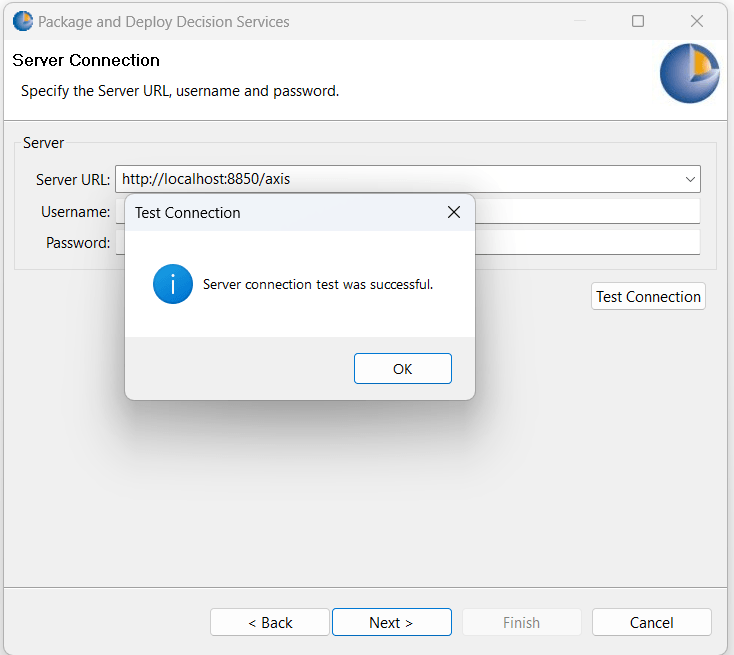
Only authorized users can login to the console.

First, double click the execution target of the rule test:
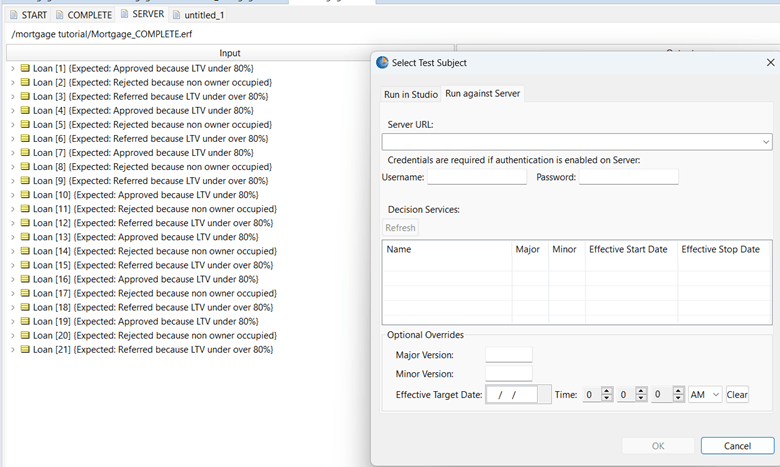
Toggle to ”Run Against Server” and enter server credentials:
The rule test will execute the test by calling the decision service endpoint on the Corticon Server instance:
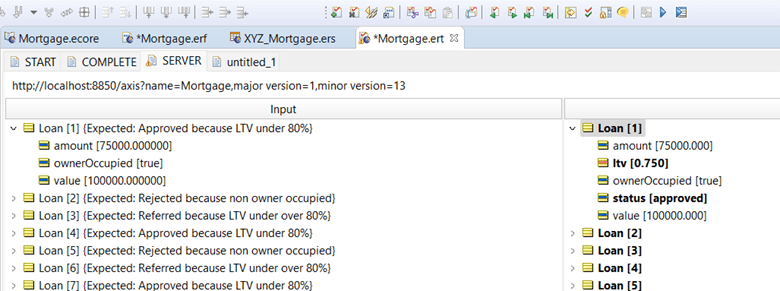
We can view the runtime statistics of the decision service by navigating to the decision service’s monitoring page on the web console.
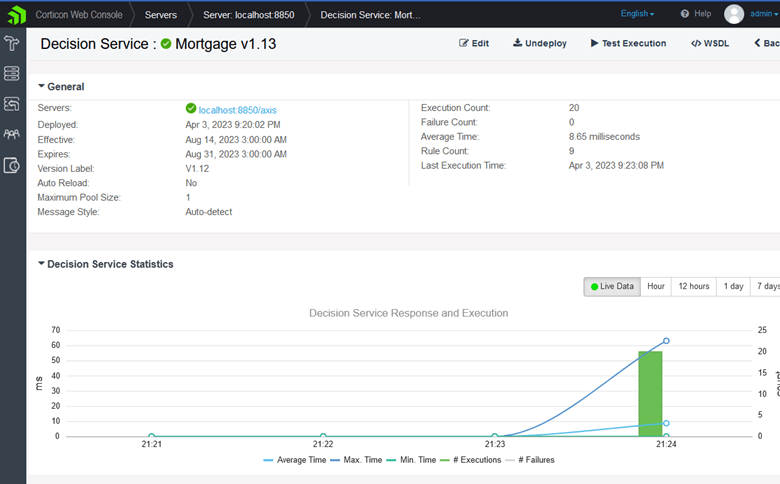
These same tests can be executed from any API testing client, such as Postman or SoapUI.
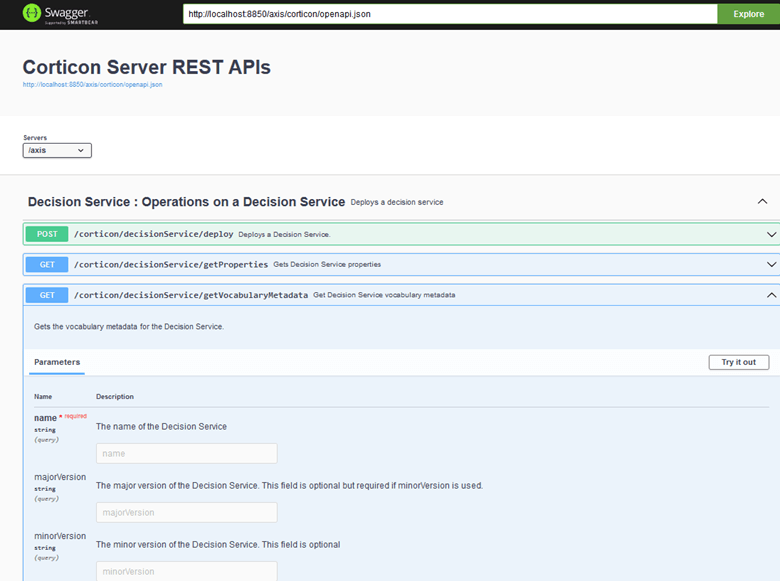
As a point of reference, we can construct a request using the ruletest parameters and the Corticon Server swagger documentation.
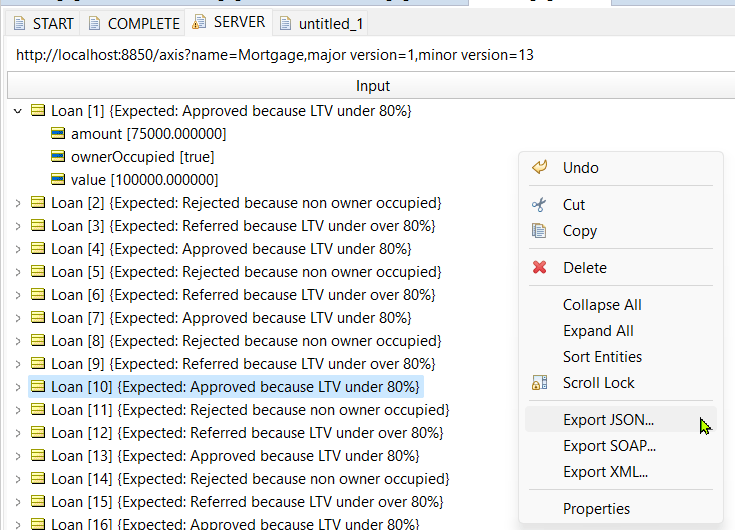
By exporting the input from the rule test request, we can build the request payload:
In a traditional (RETE) rule engine, a significant portion of the execution time is allocated to figuring out which rule to execute in which sequence. If you process one million transactions, the engine has to do this figuring out a million times.
Corticon does the figuring out ONCE at design time, and so execution performance is considerably better than RETE based engines for most business rule applications.
Additionally, Corticon scales linearly as the number of rules and the amount of data increases. RETE engines eventually reach a point where performance drops off dramatically as the data payload increases.
Because the Corticon architecture allows the rule dependencies and execution sequence to be resolved at design time (prior to runtime), a Rete engine with its runtime overhead as well as performance and scalability limitations was unnecessary. Stemmed from this observation, Corticon’s architects developed a highly efficient, highly scalable decisioning engine that executes decision services that have been optimized and compiled prior to runtime.
With this patented inferencing mechanism, Progress Corticon addressed the other major shortcoming of early rule engines: performance and scalability. Check out this whitepaper to learn more about Corticon’s inferencing capabilities.
Read the Whitepaper
Continue reading...
The Business Problem
This rule modeling case study examines how the Corticon Business Rules Management System provides a way to automate this complex scenario yet still provide the flexibility for the business experts to create and manage the rules.
Basic Rule Modeling
Identify the Business Decision(s) to be Made
Should this loan application be approved, rejected or referred for further consideration?
Collect and Review Rules Needed for Each Decision
To make this decision we will need some rules.
Here are two of the sample rules provided by the lender (there are more which we will introduce during the modeling exercise):
1. We do not currently do non owner-occupied loans
2. Loans under 80% LTV may be automatically approved
We will walk through the entire process of modeling these rules, including the discovery of errors, ambiguities and incompleteness using Corticon Studio.
We’ll find that even these two apparently simple rules contain problems which Corticon will help us discover and resolve.
Identify Business Objects (Entities)
By referring to the rule statements we can deduce the existence of objects like a loan—the entities being considered for approval.
We can also deduce that a loan will have some attributes such as:
- amount
- appraisal value
- loan to value ratio
- ownerOccupied (true or false)
- status
Status is what the rules are being asked to determine.
Create a Corticon Vocabulary
This will be modeled in the Corticon vocabulary:
Create Sample Data
This helps to make sure the data model makes sense.
This can be done in the Corticon Testing tool which is built into Corticon.
We can also set up some expected results to verify that our rules are producing the answers we expect.
We’ll see during the demo how Corticon will automatically compare the actual and expected results and flag any variations once the rules have filled in the output column.
Decide How the Rules Need to be Grouped into Rulesheets
There are no hard and fast rules about how to divide up the rules into groups, but a good way to start is to group the rules according to the main attribute that they are determining.
In this example we only have one sheet.
These are the rule statements that would be on the rulesheet. The rule statements are always the starting point for rule modeling.
Rule Modeling
Model Rules #1 and #2
Now we are ready to model the rules.
For Each Rule Statement Create a Rule Column that Connects the Conditions to the Actions
Here’s what the rules might look like:
Write Natural Language Statements if Desired
Note that it’s also possible to toggle this view to a natural language view:
At this point it appears that we are done. Our rules seem to correspond to what was in the original specification. But are they correct?
If we were developing these rules in a programming language or even a different rule engine we’d probably need to run some tests to see if the rules are correct.
In the Corticon world we don’t believe that’s the most effective way of finding errors and so Corticon has built into Studio some tools for checking the rule model.
However, for the purposes of this case study, let’s do things that way other rule engines would have to do it—with test data.
Run Test Cases
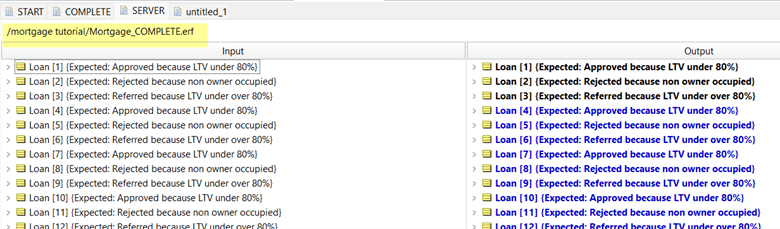
We already have some test data and expected results so we can run our rules.
This is what we will get:
Note the second test case is highlighted in red because the actual result did not match the expected result.
But why is that?
If we select loan[2] in the middle column, you will see that two rule statements are highlighted below—these are the ones that apply to loan[2].
Notice that the first did get the correct answer. However, a second rule also fired and overwrote the correct answer with an incorrect answer.
This is what we call a rule conflict or ambiguity.
Now we discovered this with test data—and for this simple example there aren’t very many possible test cases. But in the real world there may be thousands or millions of possible test cases. The chances of finding problems that way are very slim and often don’t happen until the rules are in production and an angry customer complains.
Check for Rule Ambiguity
Corticon has a much better way.
Let’s return to the rule sheet and see how Corticon can find this problem without the need for test data.
If we run the conflict checker, we’ll see this:
Corticon has determined that the conditions are not sufficient to distinguish these two rules and since they have different actions it considers them a potential ambiguity.
So, how do we resolve it?
Well, you might say, “Just put them in the other order and everything will be fine.”
Yes, in this simple case that’s true, but when there are dozens of rules it may not be obvious what the correct order is. And in any case, it’s the rule engine’s job to figure out the order.
In order to resolve this, we need to clarify the intent of the rules.
As specified it appears that rule 2 was intended to deal owner occupied loans.
This can be modeled as follows:
And now, without having to run any test cases, Corticon can confirm that this is ambiguity free.
If we choose to rerun the test case we will find that we now get the expected answer for loan 2:
Check for Rule Completeness
But notice that we still have a discrepancy. Loan 3 did not get a status assigned. That means somehow our rules are incomplete.
We can run the completeness checker and Corticon will identify any missing rules:
Rule Changes
Rules rarely stay the same for very long.
So we might imagine that this first rulesheet represents our default approval rules that apply to everyone.
Suppose one of our clients (say client XYZ) want to use slightly different rules for all of their loan approvals.
We have a number of ways we can implement this:
1. We can provide an alternative rulesheet that applies just to client XYZ.
2. We can allow client XYZ’s rules to override our default rules.
3. We can constrain client XYZs rules to fit within our default rules.
The first step is to create a fresh rulesheet for client XYZ. This is done by copy/pasting the existing rulesheet.
Then we need to do two things:
1. Indicate that this new sheet applies only to client XYZ.
2. Make the changes that are specific to XYZ.
Here’s what that might look like:
Of course, we should check this for completeness and consistency, and Corticon will discover that we are missing some rules:
Ruleflows
Now that we have two rulesheets (one generic and one for XYZ) we can configure them using the ruleflow:
In the first ruleflow, the global rules go first and the XYZ rules can override them.
In the second case, the XYZ rules go first but can be constrained or overridden by the global rules.
Only XYZ users would be able to change the XYZ rules, whereas corporate users would be able to change the Global rules (and the XYZ rules if needed).
Effective Dating of Decision Services
We can specify effective dates for a rule flow:
This dialog specifies that the rule flow will become effective on 8/14/2023 and expire on 8/31/2023.
If a rule flow with a higher version number is deployed with an overlapping effective date, then that new one will supersede this one.
Advanced Rule Modeling
Most rule engines can model the simple rules that we’ve looked at so far.
But they may not be able to handle the analysis and testing quite so well.
What happens when it gets more complex?
It can get more complex in two ways:
1. More attributes, more conditions and more combinations of conditions
2. More complex data structures and relationships between them
In this section we’ll look at how Corticon’s unique features make it easy for a businessperson to model rules that must deal with complex data structures. In many other rule engines this is a task that may have to be done by a programmer.
Loans are usually associated with customers and loans will typically have one or more payments.
Vocabulary for Complex Data Structures
This leads to the following vocabulary:
Sample Complex Hierarchical Data
Here’s a sample of some data that conforms to this structure:
Suppose we want to sum the principal payments to determine the outstanding balance.
Identifying the Context of a Rulesheet Using Scope
The key to this is Corticon’s concept of SCOPE.
When we do the summing of amounts, we want to make sure that it’s the sum of the transactions that belong to the accounts that belong to the client.
To indicate this hierarchy, we drag the entities into the scope section:
We can also create aliases to the business objects. This will allow us to write more concise rules.
To compute the amount total we can now do something very similar to what you would do in Excel—we use the SUM operator:
Here’s a small test case:
Operators for Collections
Here are some of the other operators that are available for dealing with collections:
Deploy Decision Services
Once the rule model is complete it can be deployed to the Corticon execution engine.
Corticon offers various modes of execution:
- Deployments to a Corticon Server (covered here):
- Web Services
- In-process execution
- Serverless Deployments with Corticon.js
For the Web Services option, the Corticon Web Console can be used for management of decision services.
Only authorized users can login to the console.
The Web Console
Running Tests Against Deployed Decisions Services
First, double click the execution target of the rule test:
Toggle to ”Run Against Server” and enter server credentials:
The rule test will execute the test by calling the decision service endpoint on the Corticon Server instance:
Review Decision Service Behavior
We can view the runtime statistics of the decision service by navigating to the decision service’s monitoring page on the web console.
Using Other API Testing Clients
These same tests can be executed from any API testing client, such as Postman or SoapUI.
As a point of reference, we can construct a request using the ruletest parameters and the Corticon Server swagger documentation.
By exporting the input from the rule test request, we can build the request payload:
Why is Corticon so Much Faster than Traditional Rule Engines?
In a traditional (RETE) rule engine, a significant portion of the execution time is allocated to figuring out which rule to execute in which sequence. If you process one million transactions, the engine has to do this figuring out a million times.
Corticon does the figuring out ONCE at design time, and so execution performance is considerably better than RETE based engines for most business rule applications.
Additionally, Corticon scales linearly as the number of rules and the amount of data increases. RETE engines eventually reach a point where performance drops off dramatically as the data payload increases.
Because the Corticon architecture allows the rule dependencies and execution sequence to be resolved at design time (prior to runtime), a Rete engine with its runtime overhead as well as performance and scalability limitations was unnecessary. Stemmed from this observation, Corticon’s architects developed a highly efficient, highly scalable decisioning engine that executes decision services that have been optimized and compiled prior to runtime.
With this patented inferencing mechanism, Progress Corticon addressed the other major shortcoming of early rule engines: performance and scalability. Check out this whitepaper to learn more about Corticon’s inferencing capabilities.
Read the Whitepaper
Continue reading...