
I
Idaliz Baez
Guest

Idaliz Baez, Sales Engineer, Progress DataDirect
Idaliz Baez explains how to get real-time access to Apache Spark with Progress® DataDirect® and Apache Spark SQL.
You might need to be a Jedi to wield “the Force,” but luckily you don’t need special powers to harness the forces of Big Data for business intelligence (BI). In a recent webinar, I talked about how the high-performance data connectivity found in DataDirect technology, in conjunction with Spark SQL, allows streamlined access to your Big Data on Hadoop to help you do real-time analytics more easily.
If you didn’t make the live webinar, don’t worry—you didn’t miss out! I’ve got the replay and a recap of my out-of-this-world Spark SQL data analytics demo.
Using Hadoop and Big Data for Better BI
“Big data is what happened when the cost of keeping information became less than the cost of making the decision to throw it away.”
—George Dyson
In the galaxy far, far away, they only talk about “the Force.” In our galaxy, however, several forces are driving Big Data, including large-scale web retailers like Amazon, eBay and the devices and sensors that make up the Internet of Things (IoT). These forces generate vast amounts of data which many organizations are able to harness by saving it in Hadoop clusters.
Hadoop is the most widely adopted Big Data platform because of its easy scalability and the multitude of data access solutions on the market that expose data stored in a Hadoop Distributed File System (HDFS) using SQL. However, just because you have all this data means nothing if you can’t fully leverage it. The question then becomes: “How do I take this large amount of saved data and get real-time access to it in Hadoop so I can run analytics that will benefit my organization?”
This is where DataDirect Spark SQL ODBC and JDBC drivers, in conjunction with Apache Spark and Spark SQL, enter the stage.
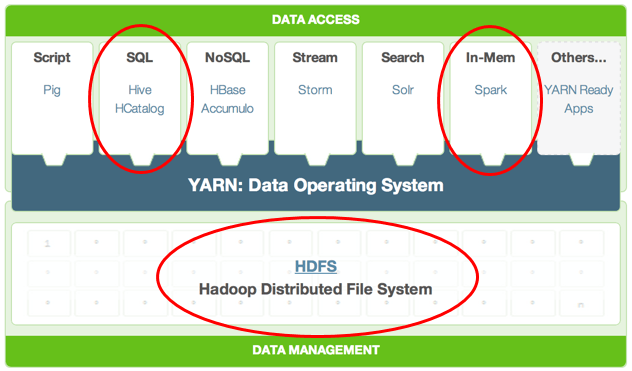
Structure of a Hadoop Database
Data Access at Super Sonic Speed
Apache Spark is a general engine for large-scale data processing. Essentially, it is a Big Data platform that provides a uniform API for workflows over diverse systems and runtimes. It is easy to use and can run everywhere, on Hadoop, standalone or in the cloud. It can access diverse data sources including HDFS, Cassandra, HBase, and Amazon S3. Perhaps the biggest advantage of Spark, however, is its speed—Spark is up to 100 times faster than Hadoop Map Reduce in memory and 10 times faster on disk.
My favorite component of Apache Spark, Spark SQL, allows you to use standard ODBC and JDBC connectivity to leverage SQL queries on your Big Data systems through Spark. It may not sound like much, but like the Millennium Falcon, Spark’s got it where it counts.
Of course, Han Solo would have never made the Kessel Run in less than 4 parsecs without a hyperdrive. In the case of Spark, the hyperdrive is the supercharged data connectivity from DataDirect. Our Spark SQL ODBC and JDBC drivers deliver the fastest connection available between your existing business intelligence tools and Apache Spark. By leveraging this connectivity with tools like Tableau, QlikView and SAP Crystal Reports you will be able to unlock real-time predictive analytics and quickly turn Big Data into actionable insight.
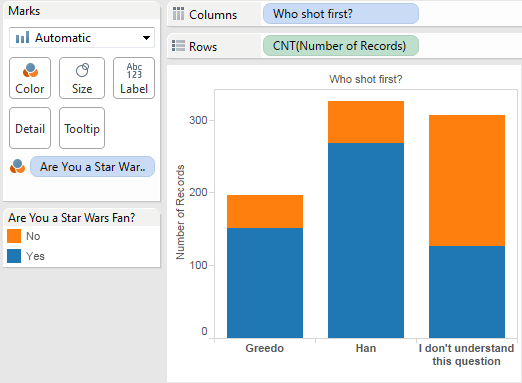
Analyzing poll data in Tableau
During the webinar, I took everyone into hyperspace by showing just how fast our SparkSQL driver can execute complicated queries to answer their most pressing business questions and even some less important questions like:
- What is the age demographic of Star Wars fans?
- How do each of the six Star Wars films rank against each other and across generations?
- Who is the best villain of the Star Wars franchise?
- Which character shot first?
To learn more about how to unlock your Big Data connectivity with Spark SQL for fast BI analysis, we invite you to watch this webinar replay. Or get started now and participate in our Apache Spark SQL ODBC and JDBC preview program.
Author information
Sales Engineer, Progress DataDirect at Progress DataDirect
Idaliz is a Sales Engineer with Progress Software. After receiving her undergraduate degree from Duke University in Civil and Environmental Engineering, Idaliz Baez spent a year at NASA Goddard Space Flight Center gaining on-the-job experience before returning to Duke in pursuit of her Masters of Engineering Management degree. Outside of the office, Idaliz can be found playing with her Australian Cattle dog or nerding out over video and board games.
|
Continue reading...