Cecil
19+ years progress programming and still learning.
I was importing a plain text file into a LONGCHAR datatype. The file had an unexpected extended character which was causing me errors. "Error -26 in file to longchar." My codepage stream & internal is set to UTF-8.
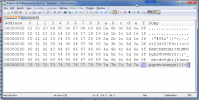
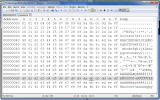
I've produced a little test code and under as UTF-8 session I seems to be only outputting 2 bytes when I was expecting 3 bytes. However if the OE session is iso8859-1 I get the expected 3 bytes.
Just for my sanity why when the OE session is UTF-8 it won't write the ascii character '150'?
Also I fixed my original code:
to this:
However the erroneous extended character is now stripped away as part of the COPY-LOB statement.
Info:
OE: 11.5 32bit
OS: Windows 7 64bit Pro.
I've produced a little test code and under as UTF-8 session I seems to be only outputting 2 bytes when I was expecting 3 bytes. However if the OE session is iso8859-1 I get the expected 3 bytes.
Just for my sanity why when the OE session is UTF-8 it won't write the ascii character '150'?
Code:
DEFINE STREAM SOUTPUT.
OUTPUT STREAM SOUTPUT TO 'asciitest.txt'.
PUT STREAM SOUTPUT CONTROL CHR(150).
PUT STREAM SOUTPUT CONTROL CHR(13) + chr(10).
OUTPUT STREAM SOUTPUT close.
FILE-INFO:FILE-NAME = 'asciitest.txt'.
MESSAGE Session:cpstream "File size: " FILE-INFO:FILE-SIZE.Also I fixed my original code:
Code:
COPY-LOB FROM FILE pchFullFilename TO OBJECT chMessageBody NO-CONVERT.
Code:
COPY-LOB FROM FILE pchFullFilename TO OBJECT chMessageBody CONVERT SOURCE CODEPAGE 'ISO8859-1' TARGET CODEPAGE 'UTF-8'.However the erroneous extended character is now stripped away as part of the COPY-LOB statement.
Info:
OE: 11.5 32bit
OS: Windows 7 64bit Pro.
")