
S
Saikrishna Teja Bobba
Guest
Learn how to access the JDBC database of your choice with AWS Glue using DataDirect JDBC drivers.
What is AWS Glue?
AWS Glue is an Extract, Transform, Load (ETL) service available as part of Amazon’s hosted web services. Glue is intended to make it easy for users to connect their data in a variety of data stores, edit and clean the data as needed, and load the data into an AWS-provisioned store for a unified view. Announced in 2016 and officially launched in Summer 2017, Glue is expected to be a popular tool on the AWS platform because it greatly simplifies the cumbersome process of setting up and maintaining ETL jobs.
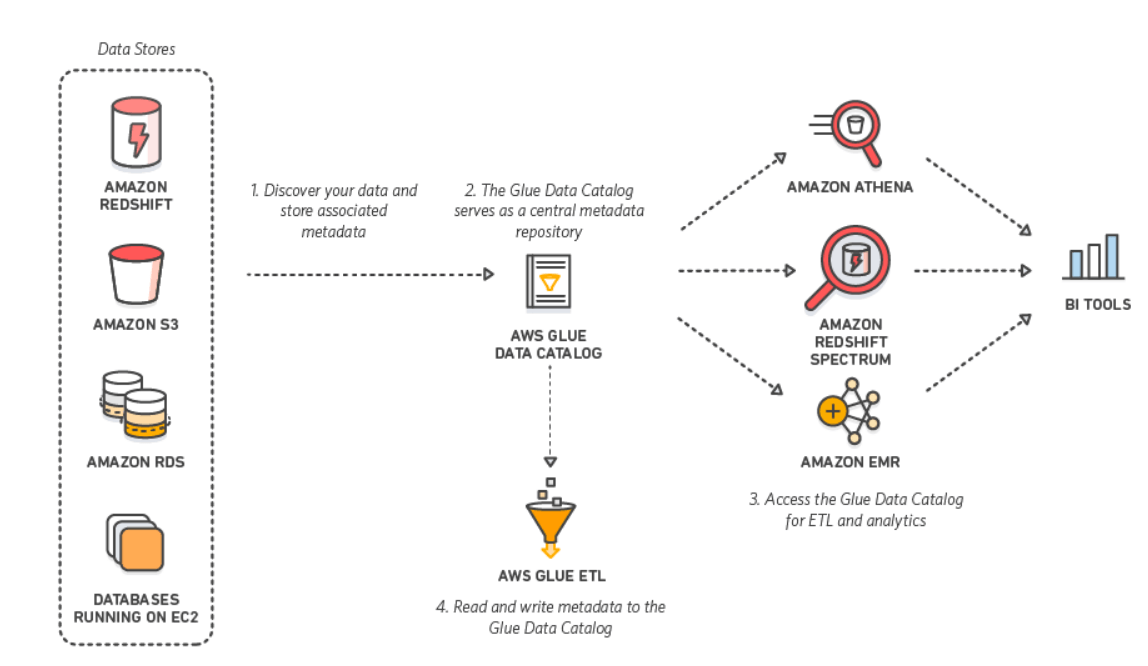
JDBC and Glue
Glue supports accessing data via JDBC, and currently the databases supported through JDBC are Postgres, MySQL, Redshift, and Aurora. Of course, JDBC drivers exist for many other databases besides these four. If you want to access any other database with JDBC, you can do so using JDBC drivers through Spark connections. The data can then be processed in Spark SQL or joined with other data sources, and AWS Glue can fully leverage the data in Spark.
Using the DataDirect JDBC connectors you can access many other data sources via Spark for use in AWS Glue. For example, this AWS blog demonstrates the use of Amazon Quick Insight for BI against data in an AWS Glue catalog. Quick Insight supports Amazon data stores and a few other sources like MySQL and Postgres. With DataDirect JDBC through Spark, you can open up any JDBC-capable BI tool to the full breadth of databases supported by DataDirect, including MongoDB, Salesforce, Oracle, and many others.
Accessing JDBC Data through Spark with DataDirect
So, how do you setup a JDBC connection to access data through Spark using a JDBC driver? Here is a quick overview of the simple steps to get started.
There is more than one way to work with your data via JDBC in Amazon Glue. If you’d like to see a different solution, we have a tutorial to help you import your external data into Spark data frames using DataDirect JDBC drivers. Once imported, you can then access the data in Spark directly with Glue, without the need for JDBC from your Glue jobs.
For more details, see this tutorial with the specific steps to access JDBC data in Spark. The example in this tutorial uses JDBC access to Salesforce data, but you can follow these exact same steps for any data source using any of the DataDirect JDBC drivers.

Get Started with DataDirect and JDBC
The industry standard for JDBC database connectivity, the Progress DataDirect JDBC drivers solve the limitations of Type 4 JDBC drivers, delivering the fastest, most scalable Java application performance. The DataDirect line of JDBC drivers supports all major databases and include advanced enterprise functionality such as application failover, bulk load, SSL data encryption, and operating system authentication using the Kerberos protocol. DataDirect also publishes a Security Vulnerability Response Policy to address all databases in a timely manner—including SaaS, big data and relational sources.
Click below to get started today with DataDirect JDBC and AWS Glue.
Get Started
Continue reading...
What is AWS Glue?
AWS Glue is an Extract, Transform, Load (ETL) service available as part of Amazon’s hosted web services. Glue is intended to make it easy for users to connect their data in a variety of data stores, edit and clean the data as needed, and load the data into an AWS-provisioned store for a unified view. Announced in 2016 and officially launched in Summer 2017, Glue is expected to be a popular tool on the AWS platform because it greatly simplifies the cumbersome process of setting up and maintaining ETL jobs.
JDBC and Glue
Glue supports accessing data via JDBC, and currently the databases supported through JDBC are Postgres, MySQL, Redshift, and Aurora. Of course, JDBC drivers exist for many other databases besides these four. If you want to access any other database with JDBC, you can do so using JDBC drivers through Spark connections. The data can then be processed in Spark SQL or joined with other data sources, and AWS Glue can fully leverage the data in Spark.
Using the DataDirect JDBC connectors you can access many other data sources via Spark for use in AWS Glue. For example, this AWS blog demonstrates the use of Amazon Quick Insight for BI against data in an AWS Glue catalog. Quick Insight supports Amazon data stores and a few other sources like MySQL and Postgres. With DataDirect JDBC through Spark, you can open up any JDBC-capable BI tool to the full breadth of databases supported by DataDirect, including MongoDB, Salesforce, Oracle, and many others.
Accessing JDBC Data through Spark with DataDirect
So, how do you setup a JDBC connection to access data through Spark using a JDBC driver? Here is a quick overview of the simple steps to get started.
- Download and locally install the DataDirect JDBC driver, then copy the driver jar to Amazon Simple Storage Service (S3). The drivers have a free 15 day trial license period, so you’ll easily be able to get this set up and tested in your environment.
- Create your Amazon Glue Job in the AWS Glue Console.
- Specify your JDBC driver as a Job parameter
- Select your Spark instance as one of your data sources in the Job
- Create the Job to copy your data from Spark to your desired destination
There is more than one way to work with your data via JDBC in Amazon Glue. If you’d like to see a different solution, we have a tutorial to help you import your external data into Spark data frames using DataDirect JDBC drivers. Once imported, you can then access the data in Spark directly with Glue, without the need for JDBC from your Glue jobs.
For more details, see this tutorial with the specific steps to access JDBC data in Spark. The example in this tutorial uses JDBC access to Salesforce data, but you can follow these exact same steps for any data source using any of the DataDirect JDBC drivers.
Get Started with DataDirect and JDBC
The industry standard for JDBC database connectivity, the Progress DataDirect JDBC drivers solve the limitations of Type 4 JDBC drivers, delivering the fastest, most scalable Java application performance. The DataDirect line of JDBC drivers supports all major databases and include advanced enterprise functionality such as application failover, bulk load, SSL data encryption, and operating system authentication using the Kerberos protocol. DataDirect also publishes a Security Vulnerability Response Policy to address all databases in a timely manner—including SaaS, big data and relational sources.
Click below to get started today with DataDirect JDBC and AWS Glue.
Get Started
Continue reading...